Echo/Feedback bei Freisprechtelefonen vermeiden, wie?
bdutta74
Selbst ein 20-Euro-Handy mit Freisprechfunktion hat keine Probleme mit Rückkopplungen. Ich verstehe zwar, dass Unternehmen wie Mediatek verrückte Mengen verwendet haben, um die Preise für mobile Chipsätze so niedrig zu halten, aber wenn ich einige Artikel lese, habe ich den Eindruck, dass die Schaltung / Elektronik Rückkopplungen von solchen Lautsprecher-Telefon-Anordnungen unterdrückt / entfernt, in denen Lautsprecher und Mikrofon platziert sind in unmittelbarer Nähe, ist ziemlich komplex (mit leistungsfähigem DSP), aufwendig und teuer. Übersehe ich hier etwas sehr grundlegendes? Gibt es im Fall von Mobiltelefonen einige Umgebungsbedingungen, die verwendet werden, um das Design solcher Schaltungen zu vereinfachen und dadurch die Kosten niedrig zu halten?
Ich nähere mich diesem aus der Studie eines el-billigen Babyphones mit 2-Wege-"Gesprächs"-Funktion, bei dem das Problem der Rückkopplung furchtbar ist. Ich habe verschiedene Dinge ausprobiert, um das Elektretmikrofon, den Lautsprechertyp dieses Geräts, zu ersetzen, ohne Erfolg. Dieser Audio-Codec, der auf diesem Gerät verwendet wird, ist anscheinend ein ALC-Codec, aber ein Großteil der Oberfläche des Chips ist geätzt, aber ich weiß, dass der Prozessor ein Winbond ARM7 ist. Es hatte oben einen glänzenden Aufkleber, den ich abkratzen konnte, um die Teilenummer zu enthüllen.
Antworten (4)
Benutzer3624
Der Audioverarbeitungsalgorithmus, an dem Sie interessiert sind, heißt "Acoustic Echo Cancellation" oder AEC. Es wird am häufigsten in Freisprechtelefonen verwendet, um die Ausgabe des Lautsprechers vom Mikrofonsignal zu entfernen. Der größte Vorteil kommt der Person am anderen Ende des Telefongesprächs zugute, da sie kein Echo von sich selbst hört.
Einige billige und nicht so billige Freisprechtelefone verwenden kein AEC. Ich habe eine Polycom-Freisprecheinrichtung, die "Halbduplex" ist. Das heißt, wenn eine Seite spricht, ist die andere Seite stummgeschaltet. Aus diesem Grund besteht keine Chance für Echos oder Rückkopplungen. Leider ermöglicht dies auch einen "Filibuster" - wenn eine Seite niemals den Mund hält, kann die andere Seite niemals unterbrechen.
Es gibt viele Arten von AEC-Algorithmen, und fast jede Art ist patentiert. Die meisten von ihnen beinhalten eine Form der Modellierung, bei der ein Modell des "akustischen Signalpfads vom Lautsprecher zum Mikrofon" erstellt wird. Nach der Erstellung können wir vorhersagen, wie der Lautsprecherausgang vom Mikrofon aufgenommen wird, und somit dieses Signal vom Mikrofon entfernen, sodass nur die beabsichtigten Töne im Mikrofonsignal verbleiben.
Dieses Modell würde also herausfinden, wie die Geräusche von den Wänden und anderen Dingen im Raum usw. reflektiert werden. Die Patente für AEC konzentrieren sich normalerweise genau darauf, wie dieses Modell ursprünglich erstellt und später aktualisiert wird, wenn sich Dinge im Raum ändern (Mikrofonposition, Position von Personen und Möbeln usw.).
Neben dem „Raummodell“ kommen weitere Rauschunterdrückungsalgorithmen zum Einsatz. Obwohl diese Algorithmen technisch nicht Teil von AEC sind, gibt es keine nützlichen Implementierungen von AEC, die diese nicht verwenden. Normalerweise gibt es eine Art einfaches Noise-Gate (oder ein Multiband-Noise-Gate). Typischerweise werden auch andere Algorithmen verwendet, die jedoch entweder patentiert sind oder als „Geschäftsgeheimnis“ behandelt werden – weshalb ich Ihnen nichts darüber erzählen kann! :(
Die meisten AEC-Algorithmen arbeiten in einem begrenzten Frequenzbereich, 300 Hz bis 3 KHz, der derselbe Frequenzbereich wie die meisten Telefone ist. Breitband-AEC wird mit dem Aufkommen von Telekonferenz-/Telepräsenzsystemen mit höherer Bandbreite immer beliebter.
AEC-Algorithmen sind sehr rechenintensiv, und die Breitband-AEC erfordert mehrere Male mehr Leistung als die eingeschränkteren Versionen. Es ist nicht ungewöhnlich, dass ein einzelner „normaler“ DSP nur 1 oder 2 AEC-Kanäle verarbeiten kann. Für eine hochwertige Breitband-AEC ist möglicherweise ein einzelner Hochleistungs-DSP für einen einzelnen Kanal erforderlich.
AEC-Algorithmen sind auch sehr schwierig zu implementieren. In den gesamten USA gibt es vielleicht nur 10 oder 20 Leute, die die Fähigkeit haben, einen guten zu schreiben. Eine sehr schlaue Person, die ich kenne, hat gerade einen Breitband-AEC-Algorithmus geschrieben und dafür über ein Jahr gebraucht!
Für ein 2-Wege-Babyphone empfehle ich dringend, einen Halbduplex-Ansatz zu verwenden!
bdutta74
bdutta74
Benutzer3624
bdutta74
Mathieu
Superkatze
Ein Ansatz, der bei kostengünstigen Freisprechtelefonen sehr verbreitet ist, besteht darin, die Verstärkung nach unten (möglicherweise auf Null) in der „Richtung“ einzustellen, die das niedrigere scheinbare Signal am Eingang hat. Einige Telefone schalten das Mikrofon stumm, es sei denn, der Audiopegel am Mikrofon ist höher, als dies der Lautsprecherrückkopplung zugeschrieben werden könnte. In diesem Fall schalten sie den Lautsprecher stumm. Andere Telefone verwenden einen adaptiveren Ansatz und schneiden den leiseren Pfad so weit ab, dass die Gesamtverstärkung der Echoschleife deutlich unter eins bleibt, aber nicht so sehr, dass beide Parteien sprechen könnten, ohne zu wissen, dass der andere dies versucht.
Eine perfekte Echokompensation ist schwierig, aber die Kombination einer einigermaßen effektiven Echokompensation mit einer adaptiven Dämpfung des „leiseren“ Signalpfads kann zu Ergebnissen führen, die subjektiv fast genauso gut sind.
bdutta74
PrakashMP
Dies ist eine sehr späte Antwort, aber ich hoffe, sie hilft einigen. Wenn Sie ein Designer sind, können Sie Echounterdrückungs-ICs von Microsemi, Cirrus Logic oder Forte Media verwenden. Sie können Ihr Teil basierend auf Ihren Anforderungen auf den Websites der Hersteller auswählen. Ich konnte keinen Echounterdrückungs-IC finden, der für weniger als 2 US-Dollar bei 3000 MOQ gekauft werden kann. Es gibt kostengünstige ARM-Chips, die Software-Echounterdrückung bis zu einem gewissen Grad unterstützen. Auch wenn ich recht habe, unterstützen viele Media-Streamer-Bibliotheken die Echounterdrückung.
Russell McMahon
Dies scheint zu behaupten, genau das zu sein, was Sie wollen
Telefonhörer-Schnittstelle mit Feedback-Steuerung pdf


Telefonhörerschnittstelle mit Feedback-Steuerung US-Patent 5867573
Und noch ein ausgewogener Modulator
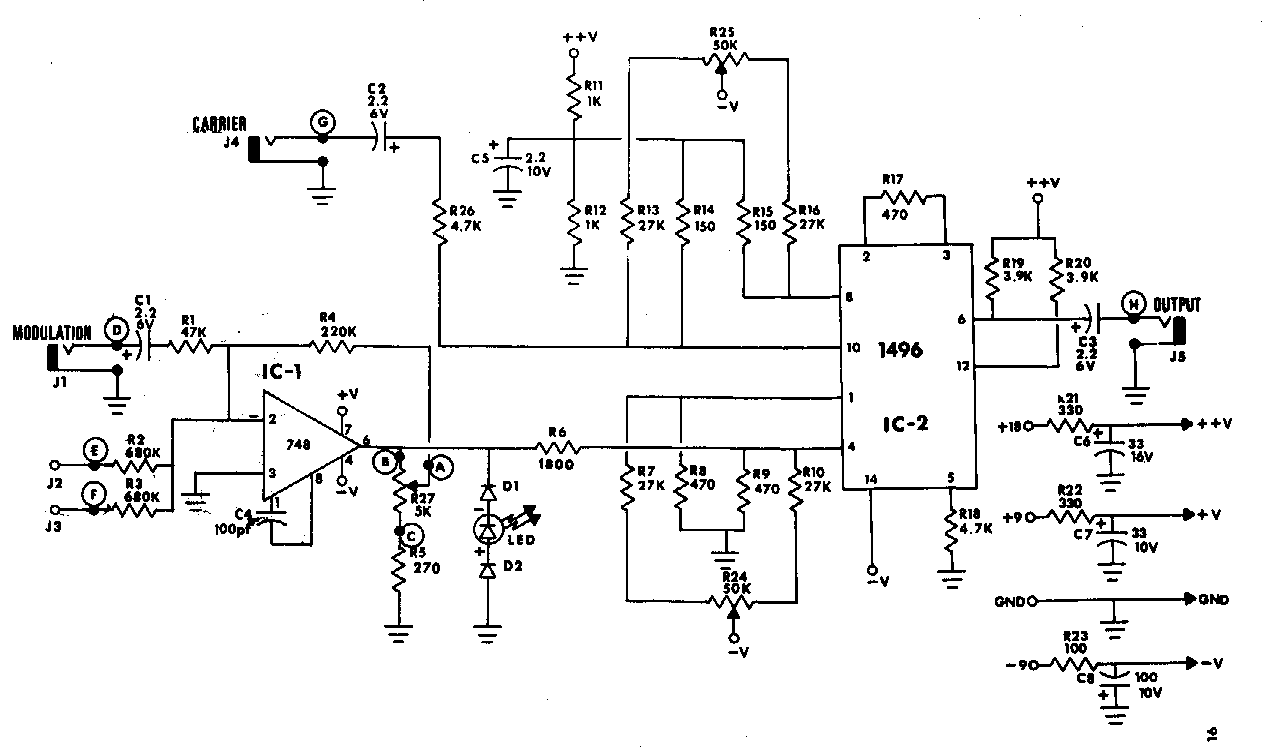{kind=link}

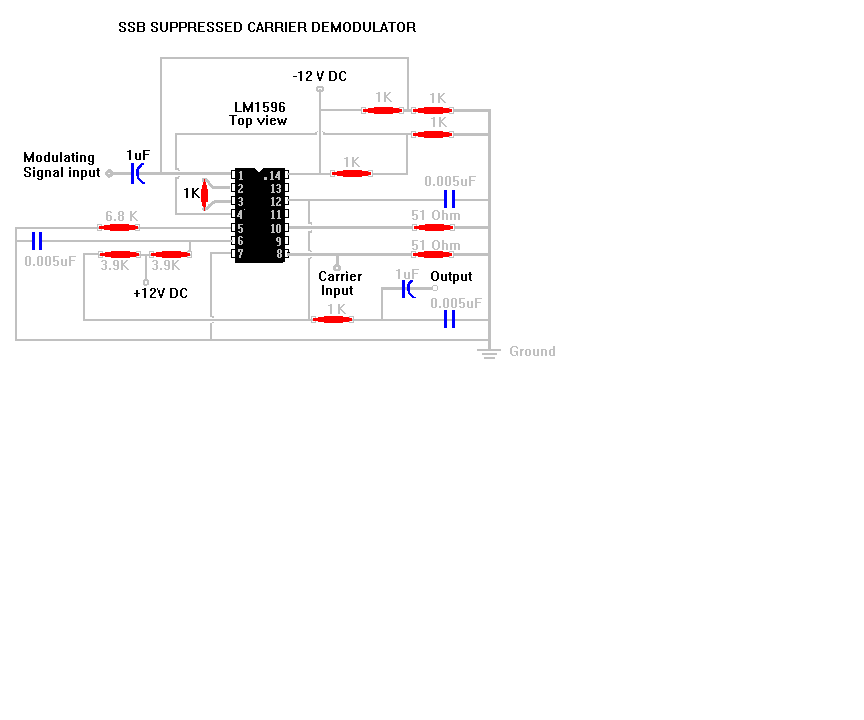{kind=link}
 . _____________________________________________
. _____________________________________________
Es werden zwei Methoden (aus ? ) verwendet
Modellieren Sie die Raumantwort mit einem Multi-Tap-Filter und optimieren Sie sie auf fehlende Korrelation mit dem Eingangssignal. Wahrscheinlich weit innerhalb der Fähigkeiten von High-End-DSPs und wahrscheinlich niedriger
Frequenzverschiebungssignal, das von Mic zu Spkr um einen festen Betrag geht, so dass jede "Heul" -Runde bei jedem Durchgang nacheinander in der Frequenz seitlich verschoben wird. Zu viel Frequenzverschiebung und Y'All spik so komisch. Zu wenig und ihr heult. Dies wurde früher mit einem analogen 4-Quadranten-Multiplikator-IC in Hardware durchgeführt und wäre heutzutage eine einfache Softwareaufgabe. - bei Werten von easy, die realtime Signale miteinander multiplizieren ;-).
Wahrscheinlich sehr einfach, wenn Sie Ihr Gehirn dazu gebracht haben, was erforderlich ist
Meine Methode 1 oben ist Abb. 5 hier

MAN SAGT:
Eine Beschallungsanwendung ist in Abbildung 5 dargestellt. Hier gibt es keine Sprache am fernen Ende, um das Modell zu speisen. Die lokale Sprache wird sofort über den Lautsprecher gesendet und ist das einzige verfügbare Trainingssignal. Die Tatsache, dass das Trainingssignal mit der lokalen Sprache korreliert ist (als Rauschen für den Trainingsprozess gesehen), stellt ein signifikantes Problem für die auf adaptiven Filtern basierende Modellierung bereit. Dies gilt insbesondere, wenn versucht wird, ein Modell aufrechtzuerhalten, das über einen breiten Frequenzbereich genau ist.
Um dieses Problem zu überwinden, wird eine Form der Dekorrelation eingeführt (z. B. eine Frequenzverschiebung). Dies unterstützt den Breitbandmodellierungsprozess, fügt dem Signal jedoch eine Verzerrung hinzu. Wie bei der Telekonferenzanwendung tritt eine weitere Verzerrung auf, wenn das Modell nicht genau ist. Die Dekorrelation zusammen mit jeder zusätzlichen Verzerrung aufgrund eines ungenauen Modells macht diese Methode für einige Veranstaltungsorte weniger attraktiv. Der große Vorteil dieser Art von Rückkopplungsunterdrückung besteht darin, dass Ihre zusätzliche Verstärkung vor der Rückkopplungsspanne normalerweise größer als 10 dB ist.
Zu meiner Methode 2 sagt das gleiche Papier (und stimmt mir heutzutage in Bezug auf DSPs usw. zu) und spikkin lustig mit zu viel Sieb.
Frequenzverschiebung
Frequenzverschiebung wird seit den 1960er Jahren in Beschallungssystemen verwendet, um Rückkopplungen zu kontrollieren. Feedback wird an Teilen der Übertragungsfunktion erzeugt, wo die Verstärkung größer als 0 dB ist. Die Lautsprecher-zu-Mikrofon-Übertragungsfunktion hat, wenn sie in einem Raum gemessen wird, Spitzen und Täler im Amplitudengang. Bei der Frequenzverschiebung werden alle Frequenzen eines Signals um einige Hertz nach oben oder unten verschoben. Die Grundidee hinter einem Frequenzumsetzer besteht darin, dass Rückkopplungen, die in einem Bereich des Frequenzgangs erzeugt werden, schließlich durch einen anderen Bereich gedämpft werden. Der Frequenzschieber verschiebt die erzeugte Rückkopplungsfrequenz weiter entlang der Übertragungsfunktion, bis sie einen Abschnitt erreicht, der die Rückkopplung effektiv dämpft. Die Wirksamkeit des Schalthebels hängt teilweise von der Systemübertragungsfunktion ab.
Es sei darauf hingewiesen, dass dies keine "musikalische Transformation" ist, da das Verhältnis zwischen den Obertönen des Signals durch die Frequenzverschiebung nicht erhalten bleibt. Die Stimme einer Person beginnt mechanisch zu klingen, wenn der Betrag der Verschiebung zunimmt. Während „hörbare Verzerrung“ von der Erfahrung des Zuhörers abhängt, sind sich die meisten einig, dass die Frequenzverschiebung weniger als 12 Hz betragen muss.
Wie viel zusätzlicher Gewinn vor Rückkopplung kann vernünftigerweise erwartet werden? Die kurze Antwort ist nur ein paar dB. Hansler1 überprüft einige Forschungsergebnisse, die darauf hindeuten, dass die tatsächlich erzielte Verstärkungssteigerung sowohl von der Nachhallzeit als auch von der Größe der Frequenzverschiebung abhängt. Durch Frequenzverschiebungen im Bereich von 6-12 Hz profitiert ein Hörsaal mit minimalem Nachhall um etwas weniger als 2 dB. Ein Echoraum mit einer Nachhallzeit von mehr als 1 Sekunde könnte von der gleichen Frequenzverschiebung um fast 6 dB profitieren.
Die digitale Signalverarbeitung ermöglicht Frequenzverschiebungstechniken in einer großen Vielfalt von Anwendungen. Bei Verwendung in Verbindung mit anderen Verfahren wie der zuvor erwähnten adaptiven Filtermodellierung kann es einen noch größeren Nutzen bieten. Die Artefakte aufgrund der Frequenzverschiebung sind jedoch in Bereichen, in denen ein reines Signal erwünscht ist, unerschwinglich. Musiker reagieren empfindlicher auf Frequenzverschiebungen, also überlegen Sie es sich zweimal, bevor Sie einen Shifter in ihren Monitorlautsprecherpfad einbauen.
Frequenzverschiebung
Meine Methode 2 ist wahrscheinlich Abb. 27 , hier verwendet MC1494 einen symmetrischen Modulator in Abb. 27. Brain sagt, dass sie zwei verwenden und das Signal zu einem Eingang von einem invertieren können, sodass Sie nur Summe oder Differenz herausbekommen und nicht beides. Beachten Sie, dass der unten kopierte Text besagt, dass der Gewinn im Gewinn gering ist. Es wäre interessant zu wissen, was passiert, wenn Sie die Frequenzverschiebung pseudozufällig streuen.
Gleich mehr.
bdutta74
bdutta74
Benutzer3624
Chris Stratton
Gibt es eine effiziente Möglichkeit, Audioereignisse mithilfe einer MCU in Echtzeit mit LEDs zu synchronisieren?
DSP-Empfehlung für Einsteiger [geschlossen]
HDMI-Mikrocontroller / DSP-Tutorial
Konfigurieren der Frequenzbandbreite und des Eingangssignals für die Bandpassfilterschaltung
Hochwertiger Audio-ADC und -DAC mit Embedded
Suchen von Spezifikationen für digitale Signalprozessoren (DSPs) für eine bestimmte Audioanwendung [geschlossen]
Bidirektionale digitale Kommunikation über Audiosignal? [geschlossen]
Kontinuierlicher digitaler Equalizer im Frequenzbereich
Kann die Signaldämpfung vom PC zum Mikrocontroller nicht verstehen (NI myRIO)
Sättigung des Audiosignals verhindern
Kellenjb
Endolith