Ich bin dabei, die offenen Daten meines Landes und die Beziehungen zwischen ihnen abzubilden, und ich muss dies sowohl in menschen- als auch in maschinenlesbaren Formaten tun.
Ich schaue mir Diagrammtools für den von Menschen lesbaren Teil an, aber ich würde das Tool benötigen, um die Ergebnisse in ein anderes maschinenlesbares Format als SQL exportieren zu können, z. B. json oder xml, um es an a weitergeben zu können selbst geschriebenes Programm zur späteren Bearbeitung.
Da ich nicht auf SQL angewiesen sein müsste, möchte ich, dass möglichst viele der UML-Beziehungstypen unterstützt werden. Ich könnte mich aber mit Assoziation, reflexiver Assoziation (Selbstreferenz) und Multiplizität begnügen.
Gibt es ein kostenloses Tool, das dies erreichen kann?
PS: Wenn nicht, gibt es Python- oder C#-Bibliotheken, die SQL-DDL-Anweisungen in eine Klassenstruktur einlesen können?
SQL Power Architect speichert seine Definition als XML-Datei. Allerdings finde ich dieses Format ziemlich schwer zu verwenden von zB XSLT.
Aber es unterstützt auch das XML-Format von Liquibase für "Forward Engineering", das einfacher zu verarbeiten ist als das Format, das Power Architect verwendet (zumindest meiner Meinung nach).
Mir ist noch etwas unklar. Könnten Sie Python nicht verwenden, um die Datenbank abzufragen und dieses Ergebnis zum Generieren von XML verwenden?
Ah, "die offenen Daten meines Landes und die Beziehungen zwischen ihnen". Also nicht unbedingt alle Daten, sondern zum Beispiel die Beziehungen zwischen Tabellen?
Wenn Sie Zugriff auf die Metadaten (Schema) haben. Wenn Sie das tun, sollte dies nicht schwierig sein. Wenn Sie dies nicht tun, können Sie SQL-Abfragen verklagen, oder sind Sie darauf beschränkt, nur Daten in einem Format zu erhalten, das sie (irgendeine Regierungswebsite) Ihnen anbieten möchten?
Zur Verdeutlichung: Um Beziehungen zwischen Daten zu ermitteln, suchen Sie am besten nach Fremdschlüsseln .
Sie können diese aus dem Datenbankschema abrufen. Oder zum Beispiel durch Ausführen des MySql- SHOW CREATE TABLEBefehls.
Diese ausgezeichnete Antwort zeigt
Für eine Tabelle:
SELECT
TABLE_NAME,COLUMN_NAME,CONSTRAINT_NAME, REFERENCED_TABLE_NAME,REFERENCED_COLUMN_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
REFERENCED_TABLE_SCHEMA = '<database>' AND
REFERENCED_TABLE_NAME = '<table>';
Für eine Spalte:
SELECT
TABLE_NAME,COLUMN_NAME,CONSTRAINT_NAME, REFERENCED_TABLE_NAME,REFERENCED_COLUMN_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
REFERENCED_TABLE_SCHEMA = '<database>' AND
REFERENCED_COLUMN_NAME = '<column>';
Natürlich ist es wahrscheinlich so, dass Sie keinen direkten Zugriff auf die eigentliche Datenbank haben, sondern nur eine API, die die Abfragen für Sie übernimmt.
Da sehe ich zwei Möglichkeiten:
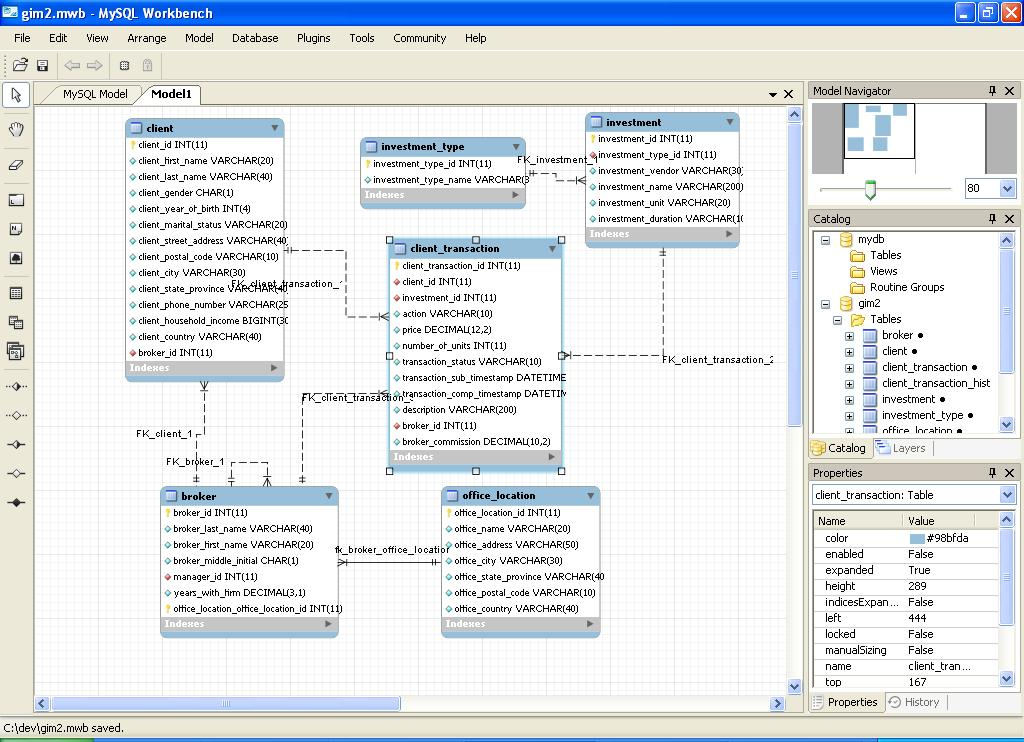
1) Wenden Sie sich an denjenigen, der die Daten bereitstellt. Wenn sie es frei verfügbar machen, werden sie wahrscheinlich nicht nur bereit, sondern sogar erfreut sein, Ihnen zu helfen. Wenn Sie wirklich Glück haben, erhalten Sie vollen Lesezugriff und können Tools wie MySql Workbench verwenden , die Ihnen helfen können, eine vorhandene Datenbank zurückzuentwickeln und sie so zu visualisieren
http://download.nust.na/pub6/mysql/tech-resources/articles/workbench-screenshot.png (Entschuldigung, mein Browser spielt ab und fügt das Bild nicht ein)
2) Dump jeden Tisch. Es wird nicht so dargestellt, aber Sie erhalten wahrscheinlich das Ergebnis von `SELECT * From ' und suchen per Hand oder per Code nach identisch benannten Spalten.
Bei einem guten Datenbankdesign werden sinnvoll benannte Spalten mit demselben Spaltennamen in mehreren Spalten verwendet. Bsp customer_id, order_idusw
Und mit gutem Datenbankdesign/viel Glück haben sie die Form <table_name¬_Id, oder <table_name>_index, oder ähnlich.
Daraus können Sie schließen, dass dies customer_idder PRIMARY KEY in der customersTabelle ist und in der Tabelle als FOREIGN KEY verwendet wird orders, wodurch Ihre Beziehung hergestellt wird.
{kind=link}
Nikolaus Raul
Mawg sagt, Monica wieder einzusetzen
Kenji Kina
Kenji Kina
Nikolaus Raul
Kenji Kina