Wie sieht der visuelle Feed von der Netzhaut aus, bevor er vom visuellen Kortex verarbeitet wird?
Benutzer1419802
Ich war kürzlich auf dem ACM Symposium on Applied Perception, wo ich eine Keynote über visuelle Aufmerksamkeit sah. Der Sprecher ( Laurent Itti ) zeigte eine Animation, die mich umgehauen hat. Es zeigte ein Video von Fischen, die im Ozean schwimmen, und daneben das gleiche Video, wie es von der Netzhaut "gesehen" wurde. Letzteres war verkehrt herum und bis zur Unkenntlichkeit verzerrt, außer an der Fovea, die im Video zu markanten Stellen herumschoss. Ich hatte schon einmal gehört, dass es erklärt wurde, dass "Ihr Auge Bilder nicht 'sieht', Ihr Gehirn rekonstruiert sie", aber ich hatte es noch nie so gut illustriert gesehen.
Ich möchte eine ähnliche Animation finden, um sie Freunden und Schülern zu zeigen, aber ich habe Probleme, etwas zu finden. Die Suche ergibt meist Diagramme von Licht, das durch das Auge fällt, oder ähnliches. Das einzige, was ich gefunden habe, das zeigt, wie ein Bild tatsächlich aussieht, wenn es die Netzhaut erreicht, ist dieses Bild.  Es ist ein netter Anfang, aber ich hätte wirklich gerne eine Animation, wie ein Video oder GIF, um zu zeigen, wie das Gehirn die Netzhautbilder bei jeder Fixierung zu einem scheinbar zusammenhängenden Bild/Video zusammenfügt.
Es ist ein netter Anfang, aber ich hätte wirklich gerne eine Animation, wie ein Video oder GIF, um zu zeigen, wie das Gehirn die Netzhautbilder bei jeder Fixierung zu einem scheinbar zusammenhängenden Bild/Video zusammenfügt.
Können Sie mir helfen, eine solche Animation zu finden? Etwas, das zeigt, wie ein roher visueller Feed tatsächlich aussieht?
Antworten (2)
Die schwarze Katze
Es gibt viel mehr zu "Ihr Auge "sieht" Bilder nicht, Ihr Gehirn rekonstruiert sie" als das, was auf diesem Bild gezeigt wird. Nachdem das Bild gespiegelt und verzerrt wurde, werden Kontrastinformationen in verschiedenen Maßstäben extrahiert und so ziemlich alles andere weggeworfen. Hier ist eine Simulation davon:
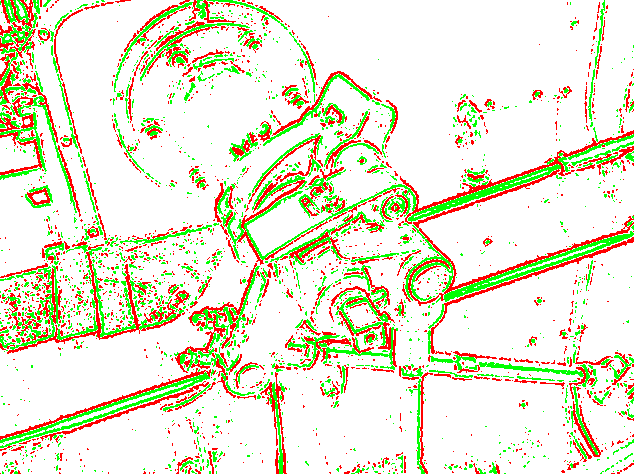
Diese Informationen werden dann verwendet, um zunehmend komplexere und abstraktere Darstellungen der visuellen Szene aufzubauen.
Ich habe ein Video gefunden , das eine Simulation zeigt, wie diese Kantenerkennung funktioniert, aber es scheint nicht die Verzerrung und die Empfangsfeldgrößen zu enthalten. Ich habe kein Video gefunden, das alles kombiniert.
Himmelstor
Es gibt einen kürzlich erschienenen Artikel über die Dekodierung von Netzhautsignalen von Primaten (Makaken)
 https://direct.mit.edu/neco/article/33/7/1719/100579/Nonlinear-Decoding-of-Natural-Images-From-Large
https://direct.mit.edu/neco/article/33/7/1719/100579/Nonlinear-Decoding-of-Natural-Images-From-Large
Gibt es einen visuellen Wasserfall-Nacheffekt mit diskreten Eingängen?
Gibt es Modelle, die beide Ströme der visuellen Verarbeitung verwenden?
Wie reagiert das Gehirn auf die über Augensakkaden gewonnenen Informationen?
Erkennen wir uns besser, wenn wir unser Spiegelbild sehen?
Gibt es eine Terminologie für Wahrnehmungstäuschungen in dem Moment, in dem die Figur-Grund-Umkehrung stattfindet?
Warum geraten die Augen der Menschen in einen unkonzentrierten Blick, wenn sie sich an eine Erinnerung erinnern oder sich etwas vorstellen?
Warum bevorzugen wir visuell ausgerichtete Objekte?
Wie die Bildorientierung die Wahrnehmung beeinflusst
Wie liest das Gehirn gedrehten Text?
Finde den Panda unter den Schneemännern!
noumenal
AliceD