Was ist die Unterrichtssprache der DNA?
Caetes
DNA trägt die meisten genetischen Anweisungen, die bei der Entwicklung, Funktion und Reproduktion aller bekannten lebenden Organismen und vieler Viren verwendet werden (Wikipedia).
Ist bereits bekannt, wie die Sequenzen von ATCG diese Anweisungen erstellen? Oder äquivalent, was ist die Unterrichtssprache der DNA? Mein Interesse an dieser Frage besteht darin, zu wissen, ob wir bereits verstehen, wie die Sequenzen von ATCG zum Beispiel menschliche Epidermis mit einem Überschuss eines bestimmten Minerals erzeugen oder die Zellform für grundlegendere geometrische Formen (Dreiecke, Rechtecke, Diamanten usw.) ändern können.
Bitte verzeihen Sie mir diese dumme Frage: Ich bin kein Biologe.
Antworten (2)
Remi.b
Diese Sprache wird genetischer Code genannt . Aber bevor wir über diesen speziellen Code sprechen, ist es wichtig, darüber zu sprechen, wie der Code gelesen wird. Bitte beachten Sie, dass die folgende Antwort eine Vereinfachung der Realität ist.
Mechanismus, mit dem der Code gelesen wird
Um die Dinge einfacher zu machen (die Realität ist etwas komplizierter), wird DNA in RNA "formatiert", die dann in Proteine "formatiert" wird. Beim „Formatieren“ verlieren wir nicht das vorherige Format, sondern kopieren die Informationen nur in ein neues Format. Die Formatierung von DNA zu RNA wird Transkription genannt und die Formatierung von RNA zu Proteinen wird Translation genannt .
Proteine sind die aktiven Einheiten, die die Zellaktivitäten beeinflussen. Die Aktivität der Proteine ist eine Funktion ihrer Sequenz. Folglich ist die Sprache/der Code, den wir verstehen müssen, die Beziehung zwischen DNA und Proteinen.
Zahlensysteme der DNA
DNA ist, wie Sie sagten, quartär geschrieben (=Zahlensystem zur Basis 4) . Die vier Buchstaben heißen A, T, C und G und stehen für Adenin, Thymin, Cytosin und Guanin ( 4 Nukleotide ).
Zahlensysteme von Proteinen
Proteine hingegen sind in einem System an Base 21 ( 21 Aminosäuren ) kodiert.
Redundanz
Da , müssen wir (mindestens) 3 Buchstaben in der DNA verwenden, um für 1 Aminosäure zu kodieren. Da , haben wir notwendigerweise mehrere Codes von 3 Nukleotiden, die zu derselben Aminosäure passen. Wir sprechen von Redundanz . In der Informatik ist ein Byte eine Folge von 8 Bits. In der Biologie ist ein Codon eine Reihe von 3 Nukleotiden.
Code
Unten ist der Code:
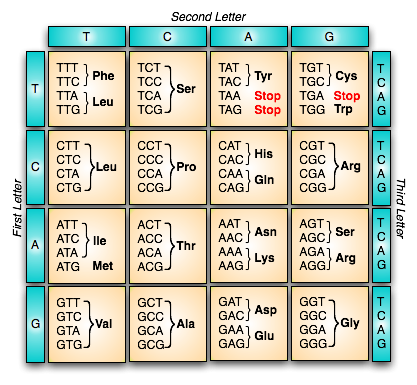
, wobei Phe, Leu, Ser, etc... eine Abkürzung für bestimmte Aminosäuren sind. Phezum Beispiel ist das Phenylallanin .
Wie Sie in der obigen Tabelle sehen können, wird der größte Teil der Redundanz durch Änderungen im dritten Buchstaben des Codons verursacht. Weitere Informationen darüber, warum dies der Fall ist, finden Sie in diesem Beitrag .
Es gibt 4 spezielle Codons.
AUG: Ist das Startcodon . Es ist ein Hinweis darauf, wo die Übersetzung beginnen sollte.UAG,UAAundUGAsind Stoppcodons . Sie sind ein Hinweis darauf, wo die Übersetzung aufhören sollte.
Mögliche Verwechslungen
Zentrales Dogma der Molekularbiologie
Die unidirektionale Beziehung zwischen DNA, RNA und Proteinen wurde als zentrales Dogma der Molekularbiologie bezeichnet . Natürlich gibt es in der Wissenschaft keinen Platz für Dogmen, und der Begriff wird sehr unsachgemäß verwendet. Interessanterweise ist das zentrale Dogma der Molekularbiologie teilweise falsch, weil diese Beziehung zwischen DNA, RNA und Proteinen nicht unbedingt einseitig ist. Die Reverse Transkriptase ist ein Enzym, das DNA aus RNA neu formatiert.
Genetischer Code
Wenn Sie "genetischer Code" googeln, wird bei den meisten Treffern der Buchstabe Uanstelle des Buchstabens angezeigt T. Der Grund dafür ist, dass der Code oft für die Beziehung zwischen RNA und DNA angegeben wird und der einzige Unterschied im Code zwischen RNA und DNA darin besteht, dass (Thymine) Tdurch U(Uracile) ersetzt wird.
mRNA vs. RNA
Nicht alle RNA soll in Proteine übersetzt werden. Nur mRNA (m steht für „Messenger“) sind. Beispielsweise wird der Übersetzungsprozess selbst durch RNA (genannt rRNA, wobei „r“ für „ribosomal“ steht) katalysiert.
Beachten Sie auch, dass DNA zuerst in Prä-mRNA transkribiert wird, die dann vor der Translation in mRNA modifiziert wird.
Wird die gesamte DNA transkribiert?
Nein. In Eukaryoten (zu denen so ziemlich alle Lebewesen gehören, die Sie sich vorstellen können, mit Ausnahme von Bakterien und Viren), wird der größte Teil der DNA nicht transkribiert. Der Rest wird für regulatorische Zwecke verwendet oder möglicherweise überhaupt nicht verwendet. Die Regionen (als Locus/Loci bezeichnet ) der DNA, die transkribiert wird, werden als Gene bezeichnet
Dexter
Matty B
David
Remi.b
David
swbarnes2
Die Funktionen von DNA und Proteinen werden durch ihre Form bestimmt, und während ihre Form hauptsächlich durch ihre Sequenz bestimmt wird, gibt es keine rechnerische Möglichkeit, Proteine von Grund auf neu zu entwerfen, um zu tun, was wir wollen. Die Modellierung ist einfach zu komplex.
Plasmid im Zellkern und Genexpression
Warum schließen sich unsere Epiphysenfugen in unseren späten Teenagern oder frühen Zwanzigern?
"Enhancer" von Enhancern?
Was passiert mit der komplementären Base, wenn die andere eine Basensubstitutionsmutation erfährt?
Gibt es DNA-Repressoren?
Aktueller Stand der Gentherapie [geschlossen]
Wie kann man die kontinentale Abstammungsgruppe (Rasse) mit Transkriptomdaten bestimmen, die mit RNA-Microarray erhalten wurden?
Welche Informationen vermitteln Microarray-Bilder?
Wie können einzelne Fellsträhnen nur eine einzige Farbe haben, wenn es um Kodominanz geht?
Welche Informationen können aus Zeitverlauf-RNA-Seq-Daten extrahiert werden?
Ro Siv
CKM
AliceD